Why imbalance happens
Leaders push for speed when markets shift, competitors move, or investors expect growth. Teams respond by starting more work. Stability slips when change volume rises faster than operational control.
Imbalance usually starts with good intent. The failure comes from invisible compounding. Every new initiative adds:
- More production change.
- More dependencies across teams.
- More cognitive load on engineers.
- More surfaces for failure.
When leaders do not name these costs, teams absorb them through longer cycles, brittle systems, and incident-driven work.

Signals you are drifting
Leaders usually notice the symptoms before they notice the cause. Treat these as early warnings, not isolated events.
- Release frequency drops even though teams feel busy.
- Incident volume rises after launches or migrations.
- Hotfixes replace planned work in multiple sprints.
- On call load concentrates on a few people.
- Customer complaints shift from features to reliability.
- Projects expand through “small” add ons that never stop.
Where leaders misstep
Misstep 1. Treating stability as overhead
Stability work protects revenue and brand. It includes resilience, observability, performance, security fixes, and runbook maturity. When leaders label this as overhead, it becomes optional. Then incidents become the delivery plan.
Misstep 2. Funding innovation without funding operations
New capabilities need support. Every new service needs monitoring, alerts, ownership, and a clear on call path. If planning stops at launch, operating costs explode later.
Misstep 3. Pushing priorities through escalation
Escalations bypass planning and break sequencing. Teams start work without clear scope or acceptance criteria. That raises rework and change failure.
Misstep 4. Measuring output instead of outcomes
Story points and project counts do not protect reliability. Leaders need measures that reflect customer impact and change quality.
What balance looks like
Balance is not fifty fifty. Balance is intentional capacity allocation plus guardrails. Leaders define where innovation is safe, where it is restricted, and what must remain stable.
Step 1. Define outcomes
- Customer value to deliver in the next 90 days.
- Reliability targets for core services.
- Non negotiables such as security and compliance.
Step 2. Name constraints
- Change windows and freeze periods.
- Team capacity and skill gaps.
- Vendor and platform limits.
Step 3. Choose capabilities to build
- Release management and rollback discipline.
- Observability and incident response maturity.
- Architecture patterns that limit blast radius.
Step 4. Select tools last
- Tooling supports the model. Tooling does not define the model.
- Prefer fewer tools with clear ownership and strong adoption.
Common executive questions
What breaks first when innovation moves too fast
Reliability breaks first. Teams push incomplete changes, bypass standards, and create operational drag. Incidents rise while delivery slows.
How leaders know balance is off
Watch for more incidents, longer recovery time, delayed releases, rising unplanned work, and increased customer escalations. If these trend up, innovation is leaking into core operations.
What to do immediately
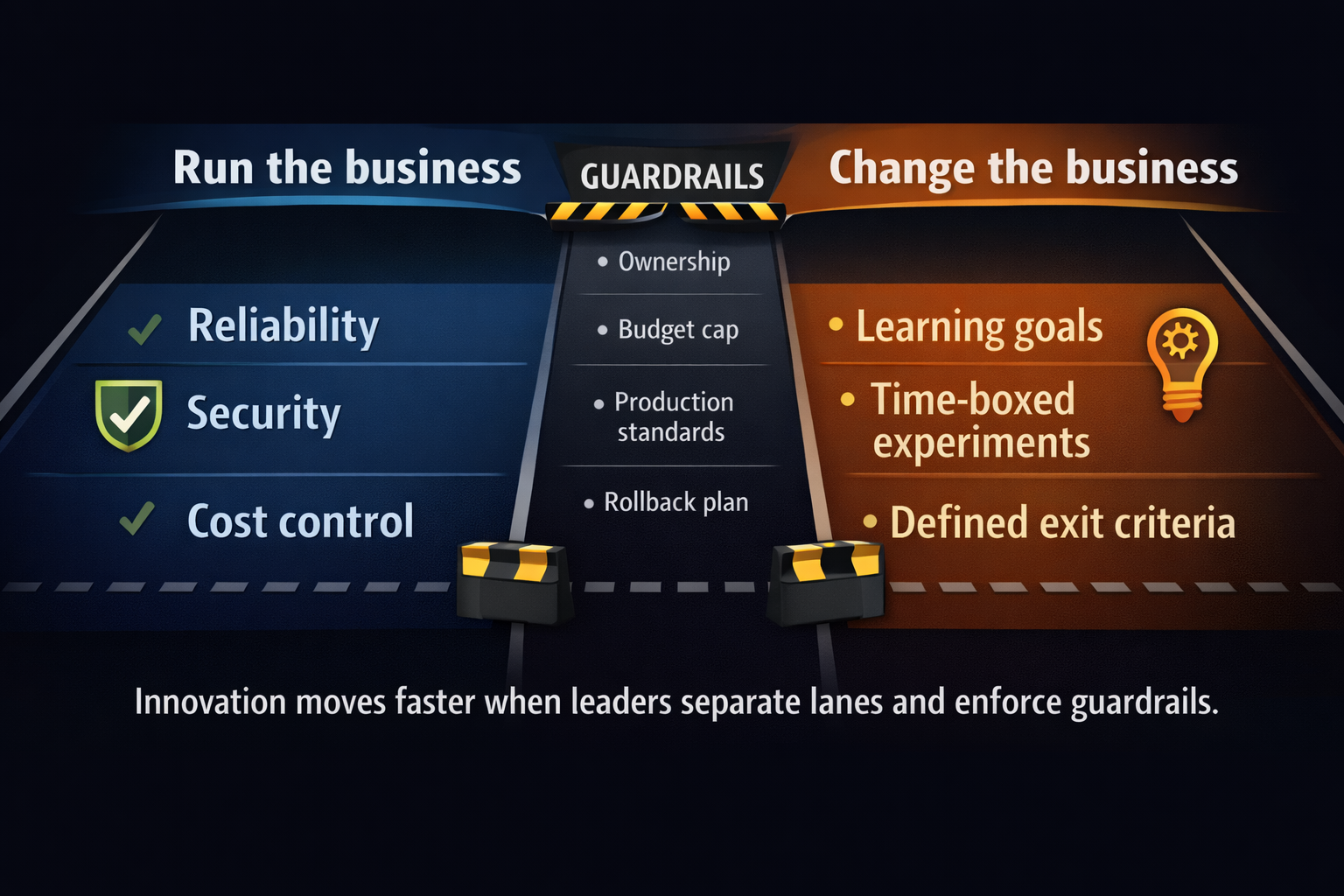
Create two lanes for work. Enforce guardrails for experiments, assign a single owner, and define exit criteria before funding or approving delivery.
Operating model and guardrails
Leaders sustain balance through an operating model that separates exploration from production change without creating silos.
- Reserve stability capacity. Many teams hold fifteen to thirty percent based on incident load.
- Define entry criteria for innovation work. Scope, owner, risk review, and success measures.
- Define exit criteria. Production readiness, monitoring, runbooks, and support ownership.
- Limit work in progress. Fewer parallel bets protects throughput and quality.
- Use change risk tiers. Low risk changes move fast. High risk changes require deeper review.
How leaders sustain it
Balance requires a cadence. Without cadence, tradeoffs happen through urgency and escalation.
Weekly operating review
- Review incidents, near misses, and customer impact.
- Review the change calendar and high risk releases.
- Confirm capacity allocation for innovation and stability.
- Decide what stops. Removing work is a leadership job.
Leadership checkpoints
Leaders approve innovation work faster when they ask better questions up front.

Metrics leaders should track
Use a small scoreboard. Review it weekly. Tie it to decisions.
- Service reliability. Availability and error rate for core services.
- Change failure rate. Percent of releases that trigger incidents, rollbacks, or hotfixes.
- Lead time. Time from approved work to production.
- Mean time to restore service. How fast teams recover when failures happen.
- Stability capacity. Percent of time reserved for reliability, security, and operational readiness.
30 60 90 day plan
First 30 days
- Document core services and owners.
- Define reliability targets and change risk tiers.
- Set the weekly operating review and decision owners.
Days 31 to 60
- Implement entry and exit criteria for new work.
- Stabilize the top incident drivers and reduce repeat pages.
- Set capacity allocation rules and enforce work in progress limits.
Days 61 to 90
- Improve release discipline and rollback practice.
- Standardize monitoring and runbooks for new services.
- Review the scoreboard trend and adjust guardrails.
Want a plan that protects innovation and stability
Bring one initiative and one core service. We will map risks, guardrails, and a 90 day operating rhythm your team will follow.
Book a consultationWhat you leave with
- A decision framework to approve innovation without destabilizing operations.
- Guardrails that keep experiments contained and measurable.
- A weekly metrics scoreboard leaders use to detect drift early.